Go Conference 2019 Spring にいってLTをした
以下のトークをしてきた。
以前書いたエントリ(BPFを用いてPostgreSQL共有バッファ読込を動的トレーシング - ujunのブログ)があり、そちらはPythonを使っておなじようなことをしているのだが、 せっかくGoConなので、Goで書いてみようと思いCFPを出したら通った。 採用していただきありがとうございます。
実はCFPを出した時点では、PythonをGo実装にすればいけるやろということでタカをくくっていたのだけど、よくよくみてみると、Goのほうのモジュールはまだだいぶ発展途上であった。USDTへのアクセスサポートしてないのは、PythonやLuaに比べてだいぶ遅れているので、なんとかしたい。ので、ちょっと思っていたような内容にはできず、BPFの説明で終わってしまった感じ。
学生の方も多く発表しており、優秀な若い人から刺激をもらったので、とても焦りを感じだけどよかった。
インフラエンジニアがあの中にいたのかは不明だけど、eBPF/BPF使う時があれば楽しいと思うよ。 *nixと付き合っていくなら、きっと必須になるはずの技術だと思う。
Kafka ConnectがTasksを分散する様子
目次
- 目次
- Kafka Connect と Producer/Consumer
- Kafka Connect のTaskとWorker
- 対象とするログ収集基盤例
- Kafka Connect REST Interface
- Workerがダウンした場合の挙動
- tasks.max を増減した場合の挙動
- 最後に
Kafka Connect と Producer/Consumer
Kafkaでデータパイプラインを構築するとき、他のデータストアとのインタフェースには以下の2通りがあると理解している。
- 自前アプリケーションでKafka APIを叩く (Producer/Consumer)
- 実装の全体を把握できるので問題発生時に細部まで対応可能と思う
- スケーラビリティを自前で担保する必要がある
- Kafka Connectを使う(Source/Sink)
ということで、自分の作りたいパイプラインに登場するデータストアに対応したプラグインがあれば、Kafka Connectを採用する方が比較的楽ができそうな気がする。ただし、自分でプラグインを書くような茨の道を行くことになりそうな場合は状況をよく吟味し、前者の方法に倒す場合もあるようだ。
Why We Replaced Our Kafka Connector with a Kafka Consumer
以下、Kafka Connect を使う前提でいくつかのデータストアと連携させる様子を記載する。
Kafka Connect のTaskとWorker
まずは Kafka Connect を構成するコンポーネントを知っておく。参照するのは以下。
Kafka Connect Concepts — Confluent Platform
Tasks
これはデータ連携元から(Sourceの場合)であったり連携先へ(Sinkの場合)データをコピーするJobを分割したもの。Connectorを作成する際のパラメータとして tasks.max に指定した数が最大分割数となる。タスク自体は状態を持たず、Kafka Server に作られる特殊なトピックあるいはConnectorインスタンスで状態管理している。
分割されたタスクは以下にあるWorkersに分散され、並行性やスケーラビリティが提供される。
Workers
Standalone とDistributed があるが、Getting Started 的な位置付けの前者は置いておく。Distributed Worker とは、実質Kafka Connect クラスタを構成するノードそのものと捉えて良いと思う。
このWorker上にConnectorインスタンスおよびタスクが分散される。例えば以下のように。

上図について追加説明をする。まず3ノードクラスタを考えている。つまりWorkerが3つある。Healthy と書かれた部分では、3ノード共が正常に稼働しており、Connectorインスタンスが1つ(C1)と実際に処理をするタスクが5つ(T1 - T5)あり、3ノードでタスクが分散されている。
Worker2 Failure と書かれた部分で、1ノードがダウンした様子が記載されている。ダウンしたノードに載っていたタスク(T2とT3)を、正常な2ノードで処理しなけれならなくなった。
Task Rebalance と書かれた部分で、T2とT3はそれぞれ別々のノードに移動し処理が継続されることが記載されている。
上記のようにタスクはFailoverしながらクラスタ内のいずれかのWorkerで処理されるようにうまくコントロールされる。
それ以外
Tasks と Workers の他に、 Converter と Transform の紹介があるが、これらはデータの加工処理に関わるコンポーネントである。本エントリでは興味の対象外とする。
対象とするログ収集基盤例
想定する簡単なログ収集基盤の概要は以下のようなものである。これ自体大した情報ではないが、この後で記載するタスク分散の挙動などは、この構成に特有のものである可能性があるので念の為書いておく。

- 各種ログをin_tailしているfluentdがfluent-plugin-kafkaで Kafka Clusterにメッセージを送信している
- Zookeeper / Kafka Broker / Kafka Connect それぞれのクラスタは同一の3ノード上に構築している
- Kafka Sink Connectorで、KafkaトピックからElasticsearchやinfluxDBに出力している。したがってConnector の Worker が3ノードである
Kafka関連の構成物は、基本的にconfluent-platformをドキュメント通りにインストールすれば問題ない。
Manual Install using Systemd on RHEL and CentOS — Confluent Platform
ElasticsearchやS3やHDFSといった代表的なデータストアのConnectorは同梱されておりそのまま使うことができるようになる。ただしinfluxDBのConnectorは自分で導入する必要がある(2019年3月時点プレビュー版のため)。Confluent公式から入手可能。ただ、自分の場合、これだとfluentdから送信されたJSONをうまく扱うことがどうしてもできず(java.util.HashMap cannot be cast to org.apache.kafka.connect.data.Struct)、以下のLandoopのものを使用した。
Kafka Connect REST Interface
Kafka Connect にはREST APIがあり、たいていのアクションがこのAPIを通して行える。
Kafka Connect REST Interface — Confluent Platform
例えば、ElasticsearchにつなげるSink Connectorを作るには以下のようなリクエストを実行する。
curl -X POST http://kafka-broker01:8083/connectors \
-H 'Content-Type: application/json' \
-H 'Accept: application/json' \
-d '{
"name": "syslog_topic_es",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"type.name": "type",
"topics": "syslog_topic",
"tasks.max": "5",
"value.converter.schemas.enable": "false",
"connection.url": "http://elasticsearch:9200",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.ignore": "true",
"schema.ignore": "true"
}
}'
直感的に理解しやすい項目として、 topics でKafka Broker上の対象トピックを、connection.url で出力先のElasticsearchを指定するなどしているが、ここで注目したいのは tasks.max である。上記の例では 5 としており、ここで指定した数値がWorkers上で展開されるTasksの数となる。
この後にTasksの状態を確認してみる。
curl http://kafka-broker01:8083/connectors/syslog_topic_es/status
{
"name": "syslog_topic_es",
"connector": {
"state": "RUNNING",
"worker_id": "kafka-broker01:8083"
},
"tasks": [
{ "id": 0, "state": "RUNNING", "worker_id": "kafka-broker01:8083" },
{ "id": 1, "state": "RUNNING", "worker_id": "kafka-broker02:8083" },
{ "id": 2, "state": "RUNNING", "worker_id": "kafka-broker03:8083" },
{ "id": 3, "state": "RUNNING", "worker_id": "kafka-broker01:8083" },
{ "id": 4, "state": "RUNNING", "worker_id": "kafka-broker02:8083" }
],
"type": "sink"
}
Connector インスタンスが kafka-broker01 ノードで稼働しており、5つのTaskが分散されて稼働している。
Workerがダウンした場合の挙動
Workerがダウンした場合、どのようにタスクがFailoverするかを観察してみる。
三番目のWorker(kafka-broker03)をstopしてみる。stopした直後に先のコマンドでstatusを確認してみると、以下のような状態を取得できた。
curl http://kafka-broker01:8083/connectors/syslog_topic_es/status
{
...
{ "id": 0, "state": "RUNNING", "worker_id": "kafka-broker01:8083" },
{ "id": 1, "state": "RUNNING", "worker_id": "kafka-broker02:8083" },
{ "id": 2, "state": "RUNNING", "worker_id": "kafka-broker01:8083" },
{ "id": 3, "state": "RUNNING", "worker_id": "kafka-broker02:8083" },
{ "id": 4, "state": "UNASSIGNED", "worker_id": "kafka-broker02:8083" }
...
},
最終的には以下のように収束した。
0 -> kafka-broker01, 1 -> kafka-broker02, 2 -> kafka-broker01, 3 -> kafka-broker02, 4 -> kafka-broker01
次にダウンしたノードを復帰してみる。ちなみに、Kafka Connect のサービスはプラグインを順次ロードしていくことになり、プラグインの数によっては起動に要する時間が膨らみがちである。Confluent Platformを通常通りインストールしただけでも標準的なプラグインが豊富に含まれるので、不要なプラグインはそもそも削除するほうが運用上は良さそうである。復帰後は以下のような状態が取得できた。
0 -> kafka-broker01, 1 -> kafka-broker02, 2 -> kafka-broker03, 3 -> kafka-broker01, 4 -> kafka-broker02
上記より、おそらく、ダウン/復帰時に必要最低限のTasksをFailoverさせるというわけではなく、task id の若番から単純に順番にWorkersにAssignされていく仕組みのようである。
tasks.max を増減した場合の挙動
REST APIから設定値を変更することも容易である。
tasks.max を変更するのには、例えば以下のようなリクエストを実行する。
curl -H 'Content-Type:application/json' -XPUT http://kafka-broker01:8083/connectors/syslog_topic_es/config -d '{
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"type.name": "type",
"topics": "syslog_topic",
"tasks.max": "10",
"value.converter.schemas.enable": "false",
"connection.url": "http://elasticsearch:9200",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.ignore": "true",
"schema.ignore": "true"
}
'
最終的な結果は以下となる。
{"id": 0, "state": "RUNNING", "worker_id": "kafka-broker01:8083"},
{"id": 1, "state": "RUNNING", "worker_id": "kafka-broker02:8083"},
{"id": 2, "state": "RUNNING", "worker_id": "kafka-broker03:8083"},
{"id": 3, "state": "RUNNING", "worker_id": "kafka-broker01:8083"},
{"id": 4, "state": "RUNNING", "worker_id": "kafka-broker02:8083"},
{"id": 5, "state": "RUNNING", "worker_id": "kafka-broker03:8083"},
{"id": 6, "state": "RUNNING", "worker_id": "kafka-broker01:8083"},
{"id": 7, "state": "RUNNING", "worker_id": "kafka-broker02:8083"},
{"id": 8, "state": "RUNNING", "worker_id": "kafka-broker03:8083"},
{"id": 9, "state": "RUNNING", "worker_id": "kafka-broker01:8083"}
Tasksを再度5に戻してみる。
{"id": 0, "state": "RUNNING", "worker_id": "kafka-broker01:8083"},
{"id": 1, "state": "RUNNING", "worker_id": "kafka-broker02:8083"},
{"id": 2, "state": "RUNNING", "worker_id": "kafka-broker03:8083"},
{"id": 3, "state": "RUNNING", "worker_id": "kafka-broker01:8083"},
{"id": 4, "state": "RUNNING", "worker_id": "kafka-broker02:8083"},
{"id": 5, "state": "UNASSIGNED", "worker_id": "kafka-broker03:8083"},
{"id": 6, "state": "UNASSIGNED", "worker_id": "kafka-broker01:8083"},
{"id": 7, "state": "UNASSIGNED", "worker_id": "kafka-broker02:8083"},
{"id": 8, "state": "UNASSIGNED", "worker_id": "kafka-broker03:8083"},
{"id": 9, "state": "UNASSIGNED", "worker_id": "kafka-broker01:8083"}
一度設定されたタスク情報が削除されることはなく、 UNASSIGNED となることがわかった。
Connectorインスタンスが稼働しているWorkerがダウンした場合の挙動
最後に、Connector インスタンスが稼働しているWorkerがダウンした場合の挙動を見る。最初に確認した通り、Connectorインスタンスは kafka-broker01で稼働している。それを落とす。
ダウン直後は以下のように Connector が UNASSIGNED となっている。
...
"connector": {
"state": "UNASSIGNED",
"worker_id": "kafka-broker01:8083"
},
...
最終的には以下の状態に収束した。
...
"connector": {
"state": "RUNNING",
"worker_id": "kafka-broker02:8083"
},
...
ざっとTasksがWorker上に分散される様子を観察した。
最後に
Kafka Connect は、よく利用されるデータストアに対しての実装は大抵用意されており、利用できる場面では推奨される。自前実装することもでき、しかも分散処理も容易に実現できるところも利点ではあるが、その場合分散システム特有の問題などが絡みトラブルシュートは辛くなるかもしれないのでよく検討する。
Tasksが分散される様子をみたが、アサインし直す場合、とにかくラウンドロビンにWorkerを割り当てていくことがわかった。巨大なクラスタでは、場合によっては、タスクの大移動が発生する可能性がありそうである。そうなったときのタスク移動の負荷は運用上無視できなくなる可能性はあるのかもしれない。
pgwatch2のミニマム設定でPostgreSQLを監視する
目次
手軽にPostgreSQLの監視をする
業務では libzbxpgsql(https://github.com/cavaliercoder/libzbxpgsql) を使ってZabbixにメトリクスを収集し、そのZabbixあるいはデータソースとしてのAmazon AuroraをデータソースとしてGrafanaでビジュアライズしている。
これには、Zabbixエージェント、Zabbixサーバ、Grafanaサーバ、DBサーバといった登場人物がいるわけだが、これをいちから準備するのはそこそこ手間である。それに、Zabbixは自由度が高く非常に便利だけれども、個人的に学習コストが高いように思う。慣れてしまうと、神がかったアイテムとトリガーとアクションを瞬時に作れるオジさんになれるのだろうが、手軽にPostgreSQLの状態をモニタリングできるツールがあれば個人用途であったり開発環境ではそっちに惹かれてしまうわけである。
目的は、ちょっとした非prodcution環境に立てただけのシングルなPostgreSQLに対して最低限の監視がしたい。ガッツリZabbixでというほどのモチベーションが湧かない。
このような時、ある程度簡単に作れてエージェントレスで素敵に可視化してくれるモニタリングツールがあると助かるが、まさにpgwatch2というのはそういう用途でガンガン使えるものになっている。
注: このエントリは、利用手順を書くものではなく、如何に簡単に始められるかに言及しており、手順が知りたい場合は、READMEがだいぶ詳しいのでそれに従うようにされたい。 -> GitHub - cybertec-postgresql/pgwatch2: PostgreSQL metrics monitor/dashboard
pgwatch2のアーキテクチャ
以下の図で大変わかりやすく説明できる。
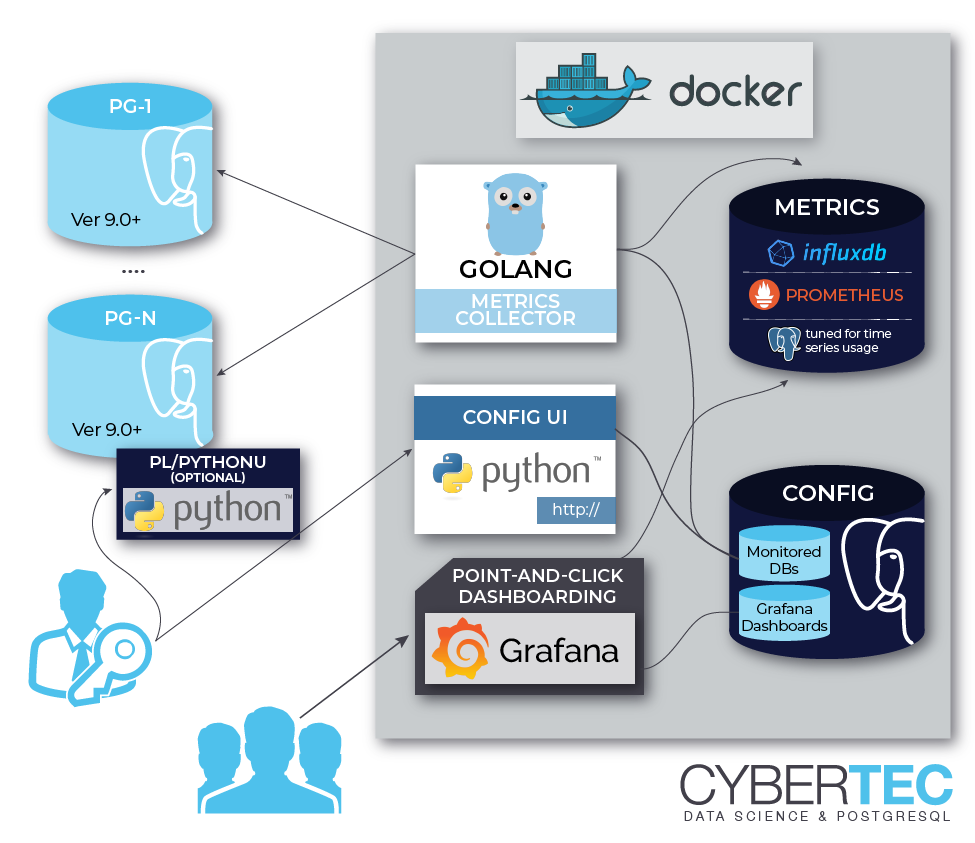
図にあるように、最も簡単な使い方はオールインワンのDockerイメージをrunするだけである。
docker run -d -p 3000:3000 -p 8080:8080 --name pw2 cybertec/pgwatch2
コンテナの中では、supervisord で influxDB、設定保存用PostgreSQL、Grafana、Metrics Collector(メトリクスの収集プロセス)、WebUI用に書かれた簡易なPythonアプリがサービスとして起動され、特に何もconfigを与えなくても docker run するだけでもう始まっている。Metrics Collectorが一定間隔(たいてい60secとか120sec)で
指定したメトリクスを収集し、influxDBに追記していく。閲覧するにはコンテナ中のGrafanaにアクセスすればよい。デフォルトではこのような構成なので、もちろんこのままコンテナを落とせば、何らかのデータ永続化を施していない限りは、設定、メトリクス、ダッシュボードすべてが吹っ飛ぶ。だがそれがいい。気軽に収集して確認して、あとは消すのにまったく手間がかからない。
ちなみに、この方法はあくまで最もシンプルな構成であって、例えば外部にinfluxDBやGrafana、あるいはChronograf等でもあれば、pgwatch2は単なるメトリクス収集くんになってもらい、データソースやビジュアライズは自前で用意しても良い。そのための設定は存在する。ただ、 docker run するだけでよいという手軽感が完全に良いのであって、他の構成をとるのであればpgwatch2にこだわる必要はないかもしれない。
準備
CREATE EXTENSION
GitHub - cybertec-postgresql/pgwatch2: PostgreSQL metrics monitor/dashboard
コンテナを上げた後(あげる前でもいいけど)、採取対象のPostgreSQLにて、 pg_stat_statements モジュールを有効化する。本エントリのタイトルでもある ミニマル設定 という主旨において必要な変更はこれだけであるとする。本来、pgwatch2の機能をフルに使うには、PL/Python を有効化したり、追加のヘルパ関数を多数追加するなどの変更が必要になるが、おそらく多くのDBaaSで PL/Python は許可されていないと考えられるので、本エントリでは度外視する。 pg_stat_statements は、Amazon RDSでもサポートされており、利用可能であることを前提とすることは自然である。
接続設定
GitHub - cybertec-postgresql/pgwatch2: PostgreSQL metrics monitor/dashboard
次に、採取対象のPostgreSQLへの接続情報を入力するが、これはコンテナの中いるPythonのWebアプリを通して行う。CherryPyというフレームワークで書かれているようだが、本当に接続情報を入力するためだけのUIとなっており、使い勝手がお察しなのが残念である。ただ初回設定時くらいにしか訪れないであろうページではある。接続情報のみに気をつけてほとんどはデフォルトでも期待の動作はするが、 Preset config を unprivileged にするよう注意する。さもなければ、Metrics Collectorから採取対象DBに対して存在しないヘルパ関数を叩き続けてしまう。
使う
influxDB
このような設定をするだけで、以下のようなmeasurementがinfluxDBの方に生成されている。
> show measurements name: measurements name ---- bgwriter db_size db_stats index_changes index_stats locks locks_mode object_changes table_changes table_io_stats table_stats wal
例えば、 db_stats というmeasurementの中には、 pg_stat_database から取得した各種フィールドがあり、
> show field keys from db_stats name: db_stats fieldKey fieldType -------- --------- blk_read_time float blk_write_time float blks_hit integer blks_read integer conflicts integer deadlocks integer numbackends integer postmaster_uptime_s integer temp_bytes integer temp_files integer tup_deleted integer tup_fetched integer tup_inserted integer tup_returned integer tup_updated integer xact_commit integer xact_rollback integer
table_stats というmeasurementの中には、 pg_stat_user_talbles から取得した各種フィールドがある。
> show field keys from table_stats name: table_stats fieldKey fieldType -------- --------- analyze_count integer autoanalyze_count integer autovacuum_count integer idx_scan integer idx_tup_fetch integer n_tup_del integer n_tup_hot_upd integer n_tup_ins integer n_tup_upd integer seconds_since_last_analyze integer seconds_since_last_vacuum integer seq_scan integer seq_tup_read integer table_size_b integer total_relation_size_b integer vacuum_count integer
Grafana
同梱のGrafanaにアクセスしてダッシュボードを作る。

まとめ
とにかく手軽にPostgreSQLの監視を構築したいときに良い選択肢になりそうである。
自前PostgreSQLクラスタを運用しているような環境なら、今回対象外とした機能も活用してリッチな監視を作ることができるし、試しても良さそう。
BPFを用いてPostgreSQL共有バッファ読込を動的トレーシング
この記事は、 Sansan Advent Calendar 2018 - Adventar 22日目のエントリです。
目次
- 目次
- AWRのSQL ordered by Readsのようにクエリごとにreadしたブロック数をPostgreSQLで知りたい
- bcc/BPFによるシステムの動的トレーシング
- PostgreSQLが提供するプローブ
- smgr-md-read-doneのコールバックで共有バッファ読込を観測するpython+c のコード
- 使用例
- Wrap-up / bccを利用した可観測性ツールが熱い
- 参考資料
AWRのSQL ordered by Readsのようにクエリごとにreadしたブロック数をPostgreSQLで知りたい
Oracle DBを運用していると、AWRやStatspackのお世話になることが多いはずである。
AWRでは、レポートの中に SQL ordered by Reads というセクションがあり、ストレージからReadしたブロック数をクエリごとに集計して表示してくれる。
普段からブロック読込の多いクエリはここを見れば把握でき、Oracleを触っていた時はここをよく見ていたし、実際に性能改善の解決の糸口になったこともあったりした。
ブロックの読込が多い傾向にあればそれはそのままロングクエリになる可能性が高いし、直感的でわかりやすい指標だと思う。
データベースのパフォーマンスというのは、永続ストレージに如何にアクセスしないで済むかということに大きく絡むため、クエリごとにメモリに読み込んだブロックを把握することはパフォーマンス改善の点で非常に有用であるのだけど、PostgreSQLではどのようにそれを観測すればいいだろうか。
bcc/BPFによるシステムの動的トレーシング
データベースの話題から一旦それる。
BPF(Berkeley Packet Filter)は、Linuxカーネル内で小さなユーザスクリプトを動作させることができる仮想マシンである。名前の通りもともとパケットフィルタツールとして 開発されたものであったが、近年においては拡張され、LinuxOSの動的トレーシングに使われるように進化してきた。例えば、特定ファイルに対するアクセスを捕捉して動作する小さなプログラムを簡単に書くことができる。
このように拡張されたBPFは、特にeBPF(enhanced BPF) と呼ばれるが、単にBPFといった時にはeBPFをさすことが多いようである。
BPFを扱う上では、bcc(BPF Compiler Collection) を使うと良い。
GitHub - iovisor/bcc: BCC - Tools for BPF-based Linux IO analysis, networking, monitoring, and more
これは、カーネルレベルの処理にCを、それをフックして動作するフロントエンドにPythonとLuaを用いてで作成することで、BPFプログラムをより簡単に書くことができる。 パフォーマンス分析やネットワークトラフィック制御など、多くのタスクに適用可能である。
bcc/BPFは、RHEL8 BetaにもTechnology previewsとして導入され、今後注目すべき技術であることは間違いない。
Chapter 6. Technology previews - Red Hat Customer Portal
さて、PostgreSQLには、BPFをはじめとした分析ツールで動的トレーシングを行う時に使えるカーネルトレースポイント(USDT probe)があらかじめいくつも定義されている。標準で提供されるモニタリングツール以上にいろいろ運用上役立つものが多そうである。
クエリごとにreadしたブロック数 といったメトリクスは、そのプローブのうちの1つを使えば採取することができる。
PostgreSQLが提供するプローブ
PostgreSQLは動的トレーシングで利用できるプローブを数多く提供しており、標準で組み込まれるプローブはドキュメントにある通りである。
PostgreSQL: Documentation: 11: 28.5. Dynamic Tracing
独自のプローブを定義することも可能であるが、デフォルトでも多くのActivityを捕捉できそう。
前提として、 PostgreSQL自体が --enable-dtrace コンパイルオプション付きでビルドされている必要がある。(なお、今回のすべてのオペレーションは、DigitalOceanのUbuntu 18.10 x64 Droplet / PostgreSQL11.1で行った)
# cd /path/to/postgresql-source # ./configure --enable-dtrace # make && make install
ちなみに、MySQLは多くのディストリビューションで、デフォルトでUSDT probe有効化されてビルドされているらしい。
smgr-md-read-doneのコールバックで共有バッファ読込を観測するpython+c のコード
上記プローブのうち、今回は smgr-md-read-done に着目する。ドキュメント的には、 ブロックの読み込み終了を捕捉するプローブ と説明されている。
以下が、特定のバックエンドプロセスにアタッチし、ブロック読込を捕捉して対象ブロック情報を表示するスクリプト。
使い方は、 blk_read_pgsql -p <postgres_backend_PID> という感じである。
bpf script for block read into shared_buffer · GitHub
CのパートとPythonのパートの中から中心的な部分をそれぞれ挙げると、
- Cの部分
いきなりインラインでCを書いているが、やりたいことは、 smgr-md-read-done の結果として得られる値を構造体に詰めて BPF_PERF_OUTPUT() でイベントとしてユーザスペースに渡している。このイベントの出力を受け付けるのがpythonパートとなる。
#include <uapi/linux/ptrace.h> struct data_t { u64 timestamp; int pid; int oid; int blkno; int requested_size; int act_size; }; BPF_PERF_OUTPUT(events); int query_blk_read(struct pt_regs *ctx) { struct data_t data = {}; data.timestamp = bpf_ktime_get_ns(); bpf_usdt_readarg(5, ctx, &data.oid); bpf_usdt_readarg(2, ctx, &data.blkno); bpf_usdt_readarg(8, ctx, &data.requested_size); bpf_usdt_readarg(7, ctx, &data.act_size); data.pid = bpf_get_current_pid_tgid(); events.perf_submit(ctx, &data, sizeof(data)); return 0; }
- Pythonの部分
smgr-md-read-done に対して先ほどCパートで定義したquery_blk_read() をコールバックとして登録している。Data クラスはイベントとして得られた値を格納する各種フィールドを持つ。イベント発生ごとに print_event() が実行される。
usdts = map(lambda pid: USDT(pid=pid), args.pids) for usdt in usdts: usdt.enable_probe("smgr__md__read__done", "query_blk_read") bpf = BPF(text=program, usdt_contexts=usdts) class Data(ct.Structure): _fields_ = [ ("timestamp", ct.c_ulonglong), ("pid", ct.c_int), ("oid", ct.c_int), ("blkno", ct.c_int), ("requested_size", ct.c_int), ("act_size", ct.c_int), ] start = BPF.monotonic_time() def print_event(cpu, data, size): event = ct.cast(data, ct.POINTER(Data)).contents print("%-14.6f %-6d %-6d %-6d %-6d %-6d" % ( float(event.timestamp - start) / 1000000000, event.pid, event.oid, event.blkno, event.requested_size, event.act_size)) print("%-14s %-6s %-6s %-6s %-6s %-6s" % ("TIME(s)", "PID", "OID", "BLKNO", "REQ", "ACT")) bpf["events"].open_perf_buffer(print_event, page_cnt=64) while True: bpf.perf_buffer_poll()
使用例
バックエンドプロセスをてきとうに選んでアタッチすると、以下のような状態で待機ループに入る。
# pgrep -al postgres ... 10834 postgres: postgres database [local] idle ... # ./blk_read_pgsql -p 10834 TIME(s) PID OID BLKNO REQ ACT
pid: 10834 からなにかクエリを発行すると、上記の待機中のコンソールに、読み込んだブロックが表示される。
たとえば以下のような結果が得られたなら、OID: 24643 のオブジェクトを最初のブロックから順に共有バッファに読み込んだことになる。きっと初めて触るテーブルをフルスキャンすればこのような結果になるはずである。
TIME(s) PID OID BLKNO REQ ACT 7.021272 10834 24643 0 8192 8192 7.022607 10834 24643 1 8192 8192 7.023180 10834 24643 2 8192 8192 7.023365 10834 24643 3 8192 8192 7.023579 10834 24643 4 8192 8192 7.023738 10834 24643 5 8192 8192 ...
pg_buffercache というcontribに含まれるextensionを使うと共有バッファの内訳を確認することができ、上記のクエリ直後だと以下のように OID: 24643 のブロックがshare_buffersに実際にのっていることがわかる。
database=# select relfilenode, relblocknumber from pg_buffercache where relfilenode = 24643;
relfilenode | relblocknumber
-------------+----------------
24643 | 0
24643 | 1
24643 | 2
24643 | 3
24643 | 4
24643 | 5
...
このあと別のバックエンドプロセスを blk_read_pgsql で観測しながら同一のクエリを流してもブロック読み込が確認できないのは、既に共有バッファに必要なブロックが存在するからであることがわかる。
ちなみに VACUUM FULL のようなOIDが変わる処理を実施するとshare_buffersからもそのブロック情報が完全に消し去られ、やはりもう一度 blk_read_pgsql で読み込みが行われることが観察できる。きっとpg_repackとかpg_reorgでも同じことが確認できると思う。
Wrap-up / bccを利用した可観測性ツールが熱い
bcc/BPFを用いて、PostgreSQLが提供するUSDTを捕捉して低レベルなメトリクスを取得した。bccではPythonによる記述が非常に強力なのでこれは使える。
RHEL8の話題というとbcc/BPFが熱いと個人的には思っている。今回のPostgreSQL動的トレーシングの例はBPFの無限の可能性のうちの1つであって、実際にBPFをベースにした活発なプロジェクトがいくつもあるようなので、要注目技術として追っていきたい。
参考資料
Microservices Get Started その1
このエントリに書くこと
このエントリは以下のようなことについて自分が最近まなんだ範囲で書く。
自分の環境は以下:
- macOS 10.13.4 - cpython 3.6.1 - nameko 2.9.1 - Docker for Mac Version 18.06.0-ce-mac70
introduction
Microservicesというワードはよく聞くし、いくつかブログや本も齧ったりしたけど、 全く自分で構築したこともないということで、いつか仕事で役立つ時がくるかもしれないしローカル環境で作ってみようと思う。
NamekoというPython製のフレームワークを使う。
可愛らしい名前だが、初心者にやさしいチュートリアル的なものが一切なく、結構使い始めるのに困るので、そういった意味でもこのエントリを書いている。
本エントリはマジでhello worldしかしてない。
GitHub - nameko/nameko: Python framework for building microservices
MicroservicesとSOA
Microservicesを始めようとする時、絶対気になるのが、 SOA(Service oriented architecture)との違いかと思われる。自分もいまだに気になる。
SOAは、S/Wエンティティ同士が細かく分割されていて、それぞれがメッセージのやりとり(SOAPとかHTTP)でコミュニケーションする。
MicroservicesはこのSOAのアドバンスドというか延長線上にいる。
ただし両者は、目的が大きく異なる。 誤解をおそれない感じで書いてみる。
SOAについて
巨大な業務システムを構築する際に、さまざまなステークホルダがいて、
それらが独自に実装したサブシステム同士が通信することを考える。
取引処理と決済処理と在庫処理が互いにデータを参照しあう時、取引システムと決済システムと在庫システムが全く別の組織が開発をしていても、
共通のインタフェースがあると、それぞれの実装はブラックボックスでもよくて、実装言語はなんでもいいしプラットフォームもそれぞれが得意なものを選択できる。
開発体制を分断できる。
ブラックボックスの先が超巨大で複雑なインフラでも、超スパゲティコードでもSOAはSOAである。
こういうこともあり、SOAは比較的S/Wの内部的なアーキテクチャに関心がない。
Microservicesについて
こちらはもっと開発品質の向上にフォーカスしている。
デリバリの効率をあげ、S/Wの開発そのものの改善を目指すもの。
したがって必然的に、S/Wの内部的なアーキテクチャに強い関心がある。
個々のサービスは、自律的かつ非依存的で、管理可能なほど小さな単位で完結しており、デプロイが容易でなければならない。
SOAPみたいなXMLのやりとりではなく,RESTやRPCを用いてコミュニケーションする。
サービス間で同じDBを参照するとかコードをシェアするとかは基本的になしである。
このように、非常に小さなサイズのサービスを包括的に管理する必要があるという意味で、
モノリシックなシステムと比較して運用がすごく難しい。
Microservicesの文脈ではコンテナが前提となっているが、運用の困難さを解決すべくOSSがいくつも出ている。
Nameko
さて、PythonでMicroservicesを書く時、Namekoというフレームワークでかなり簡単に始められる。 ちなみに、なめこが群生している様が、小さなサービスが群れているMicroservicesとなんか似ているのが由来ということらしい。 最初に触るにはよさそうである。 ただ、ドキュメントにチュートリアル的な初心者にやさしいものがないので、少し困る。
RPCについて
MicroservicesではRPCでサービス間のコミュニケーションをすることが必要となる。 これは、ネットワーク越しに存在するコードを、見かけ上はローカルのものを呼ぶかのように実行する。 RESTなどと比較して難しいのが、自分が書いているコードで、気をつけないと意図せずリモートとの通信を連発する可能性があること。 外部のリソースを使うのは高くつくものであるので、リモートコールする箇所は意識しておく必要がある。
Message Queuingについて
Namekoでは、RPCによるリモートコールを実行すると、Message Queueにリクエストを詰める。 呼び出し先のサービスでは、このキューからメッセージをconsumeしてタスクを実行する。 consumerは水平スケールすることでパフォーマンスを確保することが容易。
RabbitMQについて
メッセージのブローカとして、NamekoではRabbitMQが利用できる。 自分はDocker for Macでお手軽にローカルにRabbigMQを立てることにする。
Namekoを使って最初のMicroservices
初めてやるので、普段の環境とは分けておいた方が無難だろう。 てきとうに検証用のディレクトリを掘ってそこに移動する。
$ mkdir first_nameko; cd first_nameko
専用の仮想環境を作っておく。 (自分はcpython 3.6.1 を使った)
$ pyenv-virtualenv 3.6.1 first_nameko $ pyenv local first_nameko
Namekoをインストールする
$ pip install nameko
まずは最初の HelloWold サービスを作ってみる。
公式ドキュメントから借用して、 helloworld.py を以下の内容で作成する。
from nameko.rpc import rpc class GreetingService: name = "greeting_service" @rpc def hello(self, name): return "Hello, {}!".format(name)
サービス名は、 greeting_service である
@rpc デコレータによって、このメソッドがRPC経由で呼び出されるようにする。
次に、以下の config.yaml を同じ階層に置く。
AMQP_URI: 'pyamqp://guest:guest@localhost'
AMQP とは、NamekoがRPCをやりとりする上で利用するプロトコルらしく、今回はメッセージのブローカとしてRabbitMQを使うので、そのエンドポイントを記述。
RabbitMQにはデフォルトで guest:guest なユーザがいる。
次に、RabbitMQ自体はDockerでさくっと立てる。
$ docker run -d -p 5672:5672 -p 15672:15672 --name rabbitmq rabbitmq
そして、初めてのサービスを起動する。
$ nameko run helloworld --config config.yaml starting services: greeting_service Connected to amqp://guest:**@127.0.0.1:5672//
Namekoには cliが付属しているので、使ってみる。
$ nameko shell Nameko Python 3.6.1 (default, Sep 26 2017, 15:11:41) [GCC 4.2.1 Compatible Apple LLVM 8.0.0 (clang-800.0.42.1)] shell on darwin Broker: pyamqp://guest:guest@localhost >>>
さきほど起動したサービスに定義したメソッドを呼び出してみる。
>>> n.rpc.greeting_service.hello("ujun")
'Hello, ujun!'
このあと
Namekoを使って簡単にMicroserviceを構築できそうな雰囲気があるので、どんどん使っていきたい。
nameko.web にHTTPハンドラを作るモジュールがあるので、RESTなエンドポイントを定義してWebアプリっぽいものも簡単に作れる。
つづく
TerraformでAWS CodeDeployのアプリケーションを作る
リリース時に手で展開しているバッチを、いい加減なんらかのデプロイツールでやりたい。
できる限りTerraformで環境構築したいというのもある。
参考: https://www.terraform.io/docs/providers/aws/r/codedeploy_app.html#
素の状態から簡単にアプリケーション作るなら以下のような感じ。
# アプリケーション名
resource "aws_codedeploy_app" "sample-app" {
name = "sample"
}
# リリース時に参照するconfiguration
# 設定項目はリリースの際にどの程度のホストが正常起動している必要があるかのみ
resource "aws_codedeploy_deployment_config" "sample-config" {
deployment_config_name = "sample-config"
minimum_healthy_hosts {
type = "FLEET_PERCENT"
value = 50
}
}
# リリース対象のサーバを識別するための設定
# とりあえず `"application":"sample"` というタグがついたEC2インスタンスを対象としている
resource "aws_codedeploy_deployment_group" "sample-group" {
app_name = "${aws_codedeploy_app.sample-app.name}"
deployment_group_name = "sample-group"
service_role_arn = "${aws_iam_role.sample_codedeploy.arn}"
deployment_config_name = "${aws_codedeploy_deployment_config.sample-config.id}"
ec2_tag_set {
ec2_tag_filter {
type = "KEY_AND_VALUE"
key = "application"
value = "sample"
}
}
}
# 必要なIAMロールの設定
resource "aws_iam_role" "sample_codedeploy" {
name = "sample_codedeploy"
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"Service": "codedeploy.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
EOF
}
resource "aws_iam_role_policy_attachment" "AWSCodeDeployRole" {
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSCodeDeployRole"
role = "${aws_iam_role.sample_codedeploy.name}"
}
PowerShell で基本的なコンピュータリソースのメトリクスをとる(プロセスごと)
Windows Server 2016の検証を行なっていてもろもろとるために調べた。
(実行前に Get-Counter -ListSet process | Select-Object -ExpandProperty Paths をやらないとエラーとなることがある
参考:
同一PSで、「Get-Counter '\Process(*)\% Processor Time'」 を複数回実行するとエラーが出る
)
- CPU使用率
(Get-Counter "\Process(*)\% Processor Time").CounterSamples | select InstanceName, @{label="CPU %";expression={$_.CookedValue / $Env:NUMBER_OF_PROCESSORS -as [int]}} | where {$_.InstanceName -ne "idle" -and $_.InstanceName -ne "_total"} | sort "CPU %" -Descending
- Memory使用率
(Get-Counter "\Process(*)\working set - private").CounterSamples | select InstanceName, @{label="memory MBytes";expression={$_.CookedValue/1024/1024}}, @{label="memory %";expression={$_.CookedValue / (Get-WmiObject win32_computersystem).totalphysicalmemory }} | where {$_.InstanceName -ne "idle" -and $_.InstanceName -ne "_total"} | sort "memory %" -Descending
- IO Write Bytes/sec
(Get-Counter "\Process(*)\IO Write Bytes/sec").CounterSamples | select InstanceName, @{label="IO Write MBytes/sec";expression={$_.CookedValue}} | where {$_.InstanceName -ne "idle" -and $_.InstanceName -ne "_total"} | sort "IO Write MBytes/sec" -Descending
- IO Read Bytes/sec
(Get-Counter "\Process(*)\IO Read Bytes/sec").CounterSamples | select InstanceName, @{label="IO Read MBytes/sec";expression={$_.CookedValue}} | where {$_.InstanceName -ne "idle" -and $_.InstanceName -ne "_total"} | sort "IO Read MBytes/sec" -Descending
- Thread Count
(Get-Counter "\Process(*)\Thread Count").CounterSamples | select InstanceName, @{label="Thread Count";expression={$_.CookedValue}} | where {$_.InstanceName -ne "idle" -and $_.InstanceName -ne "_total"} | sort "Thread Count" -Descending
Get-Counterで取得できるメトリクスは以下等で確認
Get-Counter -listset * Get-Counter -ListSet process | Select-Object -ExpandProperty Paths