Ryzen 5 3600 でマシン組んだ
構成を忘れないようにメモ。
MSI B450M MORTAR MAX-A マザーボード MicroATX [AMD B450チップセット搭載] MB5512 www.amazon.co.jp
Thermaltake Versa H26 Black /w casefan ミドルタワー型PCケース [ブラックモデル] CS7070 CA-1J5-00M1WN-01 www.amazon.co.jp
玄人志向 電源 KRPW-BKシリーズ 80PLUS Bronze 650W ATX電源 KRPW-BK650W/85+ www.amazon.co.jp
Crucial SSD 250GB MX500 内蔵2.5インチ 7mm (9.5mmスペーサー付属) 5年保証 【PlayStation4 動作確認済】 正規代理店保証品 CT250MX500SSD1/JP www.amazon.co.jp
AMD Ryzen 5 3600 with Wraith Stealth cooler 3.6GHz 6コア / 12スレッド 35MB 65W【国内正規代理店品】 100-100000031BOX www.amazon.co.jp
Team DDR4 3200Mhz PC4-25600 16GBx2枚(32GBkit) デスクトップ用メモリ Elite Plus シリーズ 日本国内無期限保証 正規品 www.amazon.co.jp
玄人志向 NVIDIA GeForce GT 1030 搭載 グラフィックボード 2GB シングルファンモデル GF-GT1030-E2GB/LP/D5 www.amazon.co.jp
KubeOneでHetzner CloudにKubernetesクラスタをデプロイする
KubeOneというKubernetesの管理ツールがある。
KubeOne - Kubermatic Documentation
簡単にKubernetesクラスタをデプロイできるCLIツール(kubeadmのラッパ)で、代表的なクラウドプロバイダには対応している。 自分はおうちラボとしてよくHetzner Cloudを使っているのだけど、KubeOneはなんとHetzner Cloudに対応しており、 コマンドラインでいとも簡単にKubernetesクラスタを格安で構築することができる。検証用途であればこれで十分だと思う。 あと、Terraformに慣れている人ならきっと扱いやすくて気に入るはず。
そういうわけで、一瞬にしてクラスタを組むには以下の通り。
kubeoneのインストール https://docs.kubermatic.com/kubeone/v1.2/getting_kubeone/
Gitリポジトリをclone github.com
サンプルterraformをベースにインフラを作る https://github.com/kubermatic/kubeone/tree/master/examples/terraform/hetzner
Hetznerだと上記パスにすでにベースとなるリソースの定義があるので、例えばSSH鍵のあたりとかを自分の環境に合わせて微調整する。 デフォルトだと、コントロールプレーンのノード数が3なので3インスタンス起動するが、プロダクション環境でもあるまいし1とかにする。そしていつものように
terraform applyをするterraform outputをする
ここがKubeOneのいいところで、terraformのouputをインプットにして華麗にKubernetesをプロビジョニングする。そのために、まずは
terraform output -json > tf.jsonとする。プロビジョニングする
Kubernetesのバージョン等を記述した以下のファイルを作成(kuberone.yaml)
apiVersion: kubeone.io/v1beta1
kind: KubeOneCluster
versions:
kubernetes: '1.18.6'
cloudProvider:
hetzner: {}
external: true
そしてkubeoneを実行。 kubeone apply --manifest kubeone.yaml -t tf.json
以上。
TerraformのOutputを参照するというのが、慣れている身としては入っていきやすい
KubernetesクラスタにHetzner Cloud Controller ManagerをデプロイしてLoad Balancerをプロビジョニングする
KubernetesクラスタをHetznerCloudに秒で作ることができるようになった。また、Hetznerの永続ボリュームをプロビジョニングできるようになったので、LoadBalancer ServiceでLoad Balancerをプロビジョニングできるようにします。
前提 : kubeletの起動パラメータ
kubelet起動時に --cloud-provider=external のパラメータを渡す必要があります。RancherでKubernetesクラスタを構成する場合、以下のように In-Tree Cloud Provider の部分で External を選択すると良さそうです。

これをやらないと、後述するようなエラーが出ます。
Secretの登録
以下でHetzner CloudのAPI トークンをSecretを作ります。また、Private Network経由でトラフィックをバランシングしたいので、経由するVirtual Network名も登録します。
$ kubectl -n kube-system create secret generic hcloud --from-literal=token=<TOKEN> --from-literal=network=<NETWORK NAME> secret/hcloud created
Hetzner Cloud Controller Managerのデプロイ
まずは、以下のデプロイ用マニフェストたちをローカルに保存します。
https://github.com/hetznercloud/hcloud-cloud-controller-manager/tree/master/deploy
そして、ccm-networks.yaml 内の --cluster-cidr の部分を、自分の環境に合わせて変更(デフォルトは 10.224.0.0/16 )。
containers:
- image: hetznercloud/hcloud-cloud-controller-manager:v1.8.1
name: hcloud-cloud-controller-manager
command:
- "/bin/hcloud-cloud-controller-manager"
- "--cloud-provider=hcloud"
- "--leader-elect=false"
- "--allow-untagged-cloud"
- "--allocate-node-cidrs=true"
- "--cluster-cidr=10.224.0.0/16"
その後、以下でデプロイ。
$ kubectl apply -f /path/to/ccm-networks.yaml serviceaccount/cloud-controller-manager created clusterrolebinding.rbac.authorization.k8s.io/system:cloud-controller-manager created deployment.apps/hcloud-cloud-controller-manager created
LoadBalancer Serviceを作る
試しにてきとうなDeploymentをデプロイしておく。
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-deployment
spec:
replicas: 3
selector:
matchLabels:
app: sample-app
template:
metadata:
labels:
app: sample-app
spec:
containers:
- name: nginx-container
image: amsy810/echo-nginx:v2.0
そして、ここで起動したPodをSelectorの対象にするようにLoadBalancerの定義を記載します。
apiVersion: v1
kind: Service
metadata:
name: sample-service
annotations:
load-balancer.hetzner.cloud/location: nbg1
load-balancer.hetzner.cloud/use-private-ip: "true"
spec:
type: LoadBalancer
ports:
- port: 80
nodePort: 30080
selector:
app: sample-app
上記では、annotationsに外部LBを作成するリージョンとプライベートIPを使うことを記載していますが、他にも豊富な属性を定義できます
これをデプロイすると、外部LBが作成され、TargetとServiceも上記の定義により自動作成されます。
以下のようにHetzner Cloud ConsoleからLBができていることが確認できます。LBの名前がランダムな文字列ですが、annotationsに load-balancer.hetzner.cloud/name を指定すれば任意の名前が設定できる)
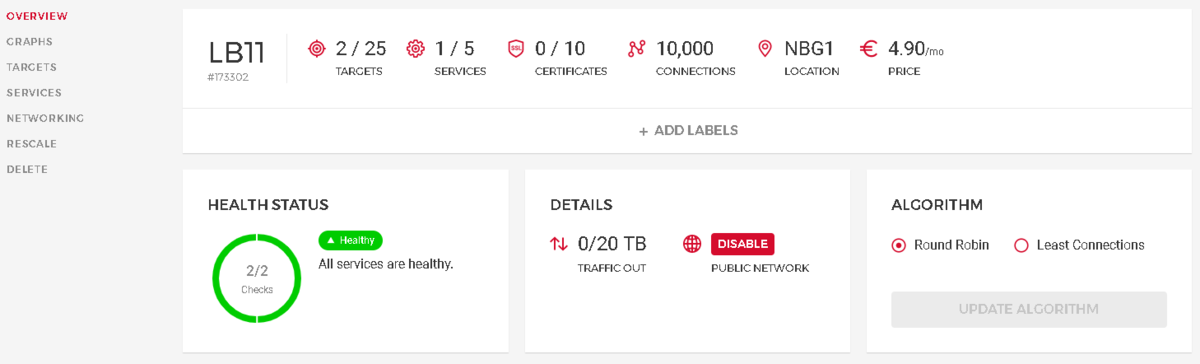
ちなみに、前提のところでkubeletの起動パラメータとして --cloud-provider=external を付与していないと、以下のようなエラーが出て、外部LBは作成できるのですが、TargetとServiceが作成されないことになるので注意。
reason: 'SyncLoadBalancerFailed' Error syncing load balancer: failed to ensure load balancer: hcloud/loadBalancers.EnsureLoadBalancer: hcops/LoadBalancerOps.ReconcileHCLBTargets: hcops/providerIDToServerID: missing prefix hcloud://:
まとめ
ボリュームのプロビジョニングはできるし外部LBのプロビジョニングはできるし、Hetzner CloudでいろいろKubernetesの検証をする準備がこれで整ってきました。
参考
KubernetesクラスタにHetznerCloudVolumes CSIをデプロイ
KubernetesクラスタをHetznerCloudに秒で作ることができるようになったので、次は、Hetznerの永続ボリュームをプロビジョニングできるようにします。
Secretの登録
HetznerのAPI Tokenを払い出して以下のようなsecretリソースのマニフェストを書いてapplyします。
apiVersion: v1
kind: Secret
metadata:
name: hcloud-csi
namespace: kube-system
stringData:
token: Token
Kubernetesバージョンに適合したCSIドライバーのデプロイ
対象のKubernetesクラスタのバージョンにあったCSIドライバーをデプロイします (適合票はGithubリポジトリ参照)
kubectl apply -f https://raw.githubusercontent.com/hetznercloud/csi-driver/v1.5.1/deploy/kubernetes/hcloud-csi.yml
StorageClassが作成されたことを確認。
# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
hcloud-volumes (default) csi.hetzner.cloud Delete WaitForFirstConsumer true 2m4s
Podを作成
作成したStorageClassを使ってVolumeをプロビジョニングしてみる。そのボリュームをテスト用のPodにアタッチ。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: csi-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: hcloud-volumes
---
kind: Pod
apiVersion: v1
metadata:
name: my-csi-app
spec:
containers:
- name: my-frontend
image: busybox
volumeMounts:
- mountPath: "/data"
name: my-csi-volume
command: [ "sleep", "1000000" ]
volumes:
- name: my-csi-volume
persistentVolumeClaim:
claimName: csi-pvc
HetznerCloudのコンソールからストレージが作成されたことが確認できます。
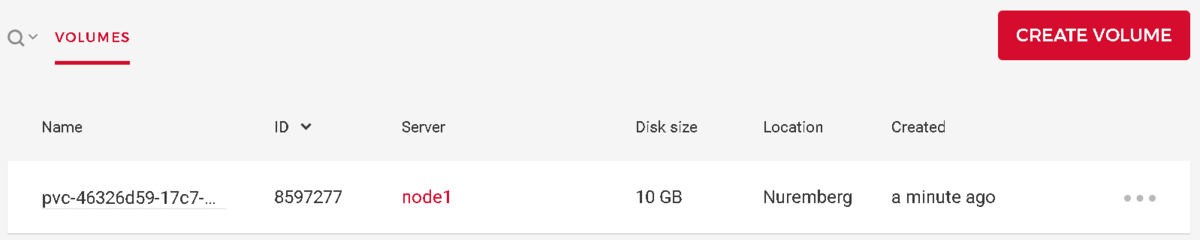
Podから状況を見ると/dataにマウントされているのがわかります。
kubectl exec -it my-csi-app -- df -h
Filesystem Size Used Available Use% Mounted on
overlay 37.5G 4.8G 31.2G 13% /
tmpfs 64.0M 0 64.0M 0% /dev
tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
/dev/disk/by-id/scsi-0HC_Volume_8597277
9.8G 36.0M 9.7G 0% /data
/dev/sda1 37.5G 4.8G 31.2G 13% /dev/termination-log
/dev/sda1 37.5G 4.8G 31.2G 13% /etc/resolv.conf
/dev/sda1 37.5G 4.8G 31.2G 13% /etc/hostname
/dev/sda1 37.5G 4.8G 31.2G 13% /etc/hosts
shm 64.0M 0 64.0M 0% /dev/shm
tmpfs 1.9G 12.0K 1.9G 0% /var/run/secrets/kubernetes.io/serviceaccount
tmpfs 1.9G 0 1.9G 0% /proc/acpi
tmpfs 64.0M 0 64.0M 0% /proc/kcore
tmpfs 64.0M 0 64.0M 0% /proc/keys
tmpfs 64.0M 0 64.0M 0% /proc/timer_list
tmpfs 64.0M 0 64.0M 0% /proc/timer_stats
tmpfs 64.0M 0 64.0M 0% /proc/sched_debug
tmpfs 1.9G 0 1.9G 0% /proc/scsi
tmpfs 1.9G 0 1.9G 0% /sys/firmware
以上
RancherのNode DriverでHetzner CloudにKubernetesクラスタを作る
手軽/安価にKubernetesクラスタを作るときに自分がやっていること。 Rancherから格安VPSであるHetzner Cloudに瞬時にクラスタを構築する。
Hetzner Cloud
Hetzner Cloudとは、Hetzner社が提供するVPSサービス(https://www.hetzner.com/cloud)で、価格が鬼のように安いです。
(2020/11現在)
| cpu(core) | memory(GB) | 価格(€/month) |
| 2 | 4 | 5.68 |
| 4 | 8 | 14.38 |
| 4 | 16 | 18.44 |
といった具合。ただし、DCは、ヘルシンキ、ニュルンベルク、ファルケンシュタインリージョンに限られるようです。 日本からSSH越しの作業をしていると、コマンド1つ1つの結果が返るまでにかなり待たされるなという感じ。 ニュルンベルクのマイスタージンガーと聞いてブギーポップを連想するお年頃なので、自分はニュルンベルクを利用することが多いです。
Rancherクラスタ
Rancherクラスタは構築済みであるとします。これはHetznerでもなんでもいいと思いますが、自分は検証用途では基本的にHetzner Cloudを使うので、Hetzner Cloudで用意。 念のため以下にRancherをシングルノードで起動するコマンドを記載(Let's Encryptで生成したサーバー証明書を使うようオプションで指定している)。
docker run -d --privileged --restart=unless-stopped -p 80:80 -p 443:443 -v /path/to/cert.pem:/etc/rancher/ssl/cert.pem -v /path/to/key.pem:/etc/rancher/ssl/key.pem rancher/rancher:latest --no-cacert
Node Driverを追加
ここらから本題。Rancherには、新規Kubernetesクラスタをプロビジョニングするとき、Infrastructure Providerという機能を利用できる。つまり、DigitalOcean、Linode 、Amazon EC2といった既存サービスを指定して、インスタンスの作成からそこにKubernetesコンポーネントを導入するところまで一気に実行する仕組みがあります。デフォルトではこれらに加えて、vSphereなどのNode DriverがActivateされていますが、Hetzner Cloudはそもそもないので、自前で導入/Activateする必要があります。
しかしNode Driverの追加はポチポチでできます(以下を参考に)。
- Rancherのグローバルメニューから、
Tools->Drivers Node Drivers->Add Node Driverを選択- フォームに以下を入力
- Download URL
- https://github.com/JonasProgrammer/docker-machine-driver-hetzner/releases/download/3.0.0/docker-machine-driver-hetzner_3.0.0_linux_amd64.tar.gz (ビルド済みのHetzner Cloud Docker machine driver)
- Custom UI URL
- Whitelist Domains
- storage.googleapis.com (UIファイルへのアクセスのため)
- Download URL
Createをクリック
Node Templateを追加
さて、Node Driverが追加されたので、あとはこれを使ってNode Templateを作成するだけです。Node Templateは、Kubernetesをプロビジョニングする際に参照される諸情報。例えば、インスタンスのサイズとか、OSイメージとか、リージョンをテンプレートとして登録できるます。
Rancher Docs: Managing Node Templates
登録したHetzner Cloud Node Driverを使ってNode Templateを登録します。
- ユーザーアバターから
Node Templateを選択する(なぜかNode Templateはユーザー設定で管理されるらしい) Add Templateを選択- すると、以下のように
Hetznerがリストの中に表示されている。TokenにHetzner側から発行したAPI Tokenを入れ、Configure Serverをクリック
hetzner01 - 最低限以下を入力しておけばOKでしょう
- Region
- Image
- Size
- Name
Createをクリック
Kubernetesクラスタをプロビジョニング
マスターノードとワーカーノード1台ずつのクラスタを構築。
- グローバルメニューから
Clusters->Add Clusterをクリック Create a new Kubernetes clusterの Infrastructure Providerを選択する部分で、Hetznerを選択- Formに従って、
Node TemplateでさきほどのテンプレートのNameを選択する - 以下のようにコンポーネントをチェックするとマスターノードとワーカーノードが1つずつとなる

hetzner02
これで待っていれば、クラスタが出来上がり。
クラスタの編集からポチポチとノード数を増やすだけで自動的にHetzner Cloudにインスタンスが生成され、スケールできるようになりました。 なんらかのモニタリングと組み合わせれば、簡単にオートスケールさせられそうなのが良いところ。
結論
Rancherを使って格安Kubernetesクラスタを構築することができました。
ちなみに、HetznerはVPS以外にも、サーバー筐体をオークションという形式でレンタルするサービスがあります。(もちろんオペレーションはすべてネットワーク越し)。 ラインナップを見ているだけでも楽しいです。
lava-dockerのPostgreSQLを捨てて Amazon Aurora Serverless を使えるように改造する
IoT的なネタと見せかけてただの魔改造を。。
目次
LAVAとは
Introduction to LAVA — LAVA 2020.04 documentation
LAVAはいろんな物理ボードとかQEMUとかでカーネルをブートしてテストするためのツール。LinuxカーネルやAndroidカーネルのパフォーマンス測定とか電力消費のモニタリング用途とかで使われることもあるそう。
なお、LAVA自身はテストスイートでもビルドファームでもなくて、どこかでビルドしたカーネルをダウンロードしてターゲットボードにデプロイしてテストを流すことができるくん なので、カーネルのビルドは自分でどこかでやっておく必要がある。例えばJenkinsと組み合わせてCIパイプラインを構築するための構成要素というのが実践的な使い方になる。
LAVAのアーキテクチャ
ざっくり以下の公式の図みたいな感じで、Master/Workerから構成されていて、Workerをスケールさせれば大量のターゲットボードに対して実行することができるようになる。

図をみると、LAVAのデータストア(PostgreSQLです)はMasterノードからのみアクセスされ、しかもMasterノードのローカルにある。公式のインストール手順でもlava-dockerプロジェクト(https://github.com/kernelci/lava-docker)でも、Masterと同ノードあるいは同コンテナにPostgreSQLがインストールされることになる。また、ガイド(https://docs.lavasoftware.org/lava/first-installation.html) によれば以下のように書かれており、やっぱりMasterノードとPostgreSQLは抱き合わせ前提のようだ。
Database - This uses PostgreSQL locally on the master, with no external access.
基本的には可用性とか拡張性がそこまで強く求められるシステムでもないと思うので、これはこれでライトに使えるという点でいいのかもしれないけど、こういうのは外部データストアの可能性も考えたくなるものなので。。
ワークロード的に常時稼働でないこういうDev系のシステムには、Aurora Serverlessが選択肢としてあり得る、と思うけど実際どうなんだろう。とりあえずそこにDBの役割をオフロードすることを考える。PostgreSQL互換もサポートされていることだし。もちろん自前のPostgreSQLサーバとかprovisionedタイプのRDSとか、実際はなんでもイイ。
lava-dockerのインストール
VPC内にEC2インスタンスを立てる。
lava-dockerで導入するのがシンプルなので、手順(https://github.com/kernelci/lava-docker#quickstart)に従って、以下を実行する。
$ git clone https://github.com/kernelci/lava-docker.git $ cd lava-docker $ ./lavalab-gen.py
lavalab-gen.py を実行すると、output/local というディレクトリが生成されて、配下にdocker-compose用のファイルがいくつか生成されている。
例えばmasterのほうは以下のようなファイル構成となる。
master1
├── Dockerfile
├── apache2
├── backup
├── default
├── device-types
├── device-types-patch
├── devices
├── entrypoint.d
│ └── 01_setup.sh
├── env
├── groups
├── health-checks
├── lava-patch
├── lava_http_fqdn
├── settings.conf
├── tokens
│ └── admin-0
├── users
│ └── admin
└── zmq_auth
公式手順だとこのまま docker-compose build; docker-compose up -d すれば起動する。
でmasterコンテナ内のPostgreSQLがデータストアとなる。このままコンテナを作り直せばデータは揮発しちゃう。
ので、永続化させたければデータボリュームをコンテナのデータ領域にマウントするなど方法がある。今回はマネージドのDBサービスを使う。
AWS Aurora Serverless の準備
これは省略。
改造する
この方法は2020年5月時点で非公式の方法であり、なんらかのコードパスで不具合が生じる可能性があるけども、一応ちゃんと動いてくれているように見えてはいるので自分の環境はこれにしている。
とても簡単な改造の3ステップが以下のような流れ。
instance.confを作成する
masterは/etc/lava-server/instance.confという設定ファイルを参照して接続先DBを認識するようなので、以下のようなinstance.confを、てきとうなパスに作成する。で、masterのDockerfileの中にCOPY /path/to/instance.conf /etc/lava-server/instance.confを追加しておく。
※ もちろんAurora側にRoleやDBは作成済みであるとするLAVA_DB_PASSWORD="lavaserver"
LAVA_SYS_USER="lavaserver"
LAVA_DB_NAME="lavaserver"
LAVA_INSTANCE="lavaserver"
LAVA_DB_USER="lavaserver"
LAVA_DB_PORT="5432"
LAVA_DB_SERVER="endpoint of Aurora"
master1/entrypoint.d/01_setup.shを修正する
これはmasterイメージをbuildするさいのentrypointとなるスクリプトで、実はこの中で、ローカルのPostgreSQLに対してlavaserverユーザのパスワードをランダムに変更するという力技を行っている。そして、instance.confのLAVA_DB_PASSWORDも書き換えている。そのためここは以下の行をコメントアウトなり削除しておいてinstance.confへの置換を無効化する。。。< sed -i "s,^LAVA_DB_PASSWORD=.*,LAVA_DB_PASSWORD='$(cat /root/pg_lava_password)'," /etc/lava-server/instance.conf || exit $? --- > # sed -i "s,^LAVA_DB_PASSWORD=.*,LAVA_DB_PASSWORD='$(cat /root/pg_lava_password)'," /etc/lava-server/instance.conf || exit $?ビルドして起動する
あとは、docker-compose build; docker-compose up -dするだけ。
大変雑な改造なのだが、もっとちゃんとやるのであればそもそもmasterコンテナでPostgreSQLあげないようにしたほうがベターだろうと思う。
一昔前には、サーバハードニングという文脈において不要なサービスは停止することというのが当たり前のように叫ばれていたような気がする。OSインストールからハコモノを大事に育てるような素朴な構築をなかなかしなくなってしまった昨今でも大事というか普通にチェックすべしなポイントではあるけども。
なにはともあれできた。
使えている
とりあえずサンプルのジョブを流してちゃんと使えていることが確認できた。
Submitting your first job — LAVA 2020.04 documentation
コンテナ再作成しても過去のレポートやらテストのログが残るのはうれしい。RDS自体のもろもろの恩恵にもあずかれる。
今後
EC2インスタンス上でdocker-composeをしたのだけど、ここまできたらmasterとworkerもマネージドなコンテナオーケストレーションサービスを使いたいと思うのが自然なので、そうしたい。
データ自体はAuroraに保持することによってポータビリティがめっさあがったと思い、Fargateとかにマイグレーションするときもきっとすんなりいってくれるはずと思っているけどそんなことはないんだろうなあ。
参考
bpftraceでPostgreSQLのバックエンドプロセスを追う
これは、Sansan Advent Calendar 2019 - Adventar の24日目のエントリーです。
PostgreSQLのUSDTを題材にしてbpftraceワンライナーをいくつか書いていきます。ここではuprobeは対象外としています。
はじめに
前提としてこれは遊びであり、PostgreSQLはマルチプロセスであるということから、現時点でよさげなUSDTトレーシング手法(つまり生まれては消えるバックエンドプロセスやらautovacuumワーカーやらパラレルクエリで起動するサブプロセスやら常駐するバックグラウンドプロセス全体を対象として隈なくUSDTを補足する方法)が見つけられない。USDTを補足する場合、既存のプロセスにアタッチする形をとるためである。
このような話題は以下で確認することができる。
一方でMySQLはスレッドモデルであり、プロセス全体としてUSDTを覗くのに適しているし、そのような例はググれば確かに見つかるし、今月発刊された以下の書籍のchapter13を通してMySQLの分析が出ており、こちらのほうが試し甲斐がきっとあるのだろう。自分としてはMySQLをあまり業務でさわったことがないが。
ただ、bpftraceは生のBCCと比較すると、よりアドホックな分析のために使われることが多く、何か現実に問題があったときにそのプロセスを対象として実施されることが多いはずで、各論的なアプローチがうまくいけば目的として十分達成されているというスタンスな気がする。
ということであるが、まずはbpftraceでPostgreSQLを追うに際して、利用できるUSDTを確認しておく。以下をver11.2で確認。
# bpftrace -l 'usdt:/usr/pgsql-11.2/bin/postgres' usdt:/usr/pgsql-11.2/bin/postgres:postgresql:clog__checkpoint__start ... ... usdt:/usr/pgsql-11.2/bin/postgres:postgresql:query__execute__start usdt:/usr/pgsql-11.2/bin/postgres:postgresql:query__execute__done usdt:/usr/pgsql-11.2/bin/postgres:postgresql:sort__start usdt:/usr/pgsql-11.2/bin/postgres:postgresql:sort__done
50個以上ある。
PostgreSQLのUSDTを題材にしてトレーシングの練習をしてみる。
クエリのライフサイクル
上記のUSDTの中で、バックエンド処理に関連しそうな query_* とか sort_* というUSDTを対象として、タイムスタンプとprobeをprintするワンライナーで実際に実行されている様子を観察すると以下のようになった。
# bpftrace -e 'usdt:/usr/pgsql-11.2/bin/postgres:postgresql:query_* { printf(
"Passed: %ld, %s\n", nsecs, probe)} usdt:/usr/pgsql-11.2/bin/postgres:postgresql:sort_* { prin
tf("Passed: %ld, %s\n", nsecs, probe)}' -p <pid>
Attaching 12 probes...
Passed: 408581588562048, usdt:/usr/pgsql-11.2/bin/postgres:postgresql:query__start
Passed: 408581588617673, usdt:/usr/pgsql-11.2/bin/postgres:postgresql:query__parse__start
Passed: 408581588759128, usdt:/usr/pgsql-11.2/bin/postgres:postgresql:query__parse__done
Passed: 408581588783823, usdt:/usr/pgsql-11.2/bin/postgres:postgresql:query__rewrite__start
Passed: 408581588942843, usdt:/usr/pgsql-11.2/bin/postgres:postgresql:query__rewrite__done
Passed: 408581588971818, usdt:/usr/pgsql-11.2/bin/postgres:postgresql:query__plan__start
Passed: 408581589172124, usdt:/usr/pgsql-11.2/bin/postgres:postgresql:query__plan__done
Passed: 408581589254474, usdt:/usr/pgsql-11.2/bin/postgres:postgresql:sort__start
Passed: 408581589399734, usdt:/usr/pgsql-11.2/bin/postgres:postgresql:sort__done
Passed: 408581589474509, usdt:/usr/pgsql-11.2/bin/postgres:postgresql:query__done
12個のUSDTが対象として登録され、バックエンド処理の話でよく解説されるようなリライト処理やプランナの処理が実行されていることがわかる。
これ自体なんてことはないが、各USDT処理のにフックして何らかの処理を行うという観点ではbpftraceが選択肢の1つに入るかもしれない。あるかわからないが。
発行されたクエリとそのduration
上記の query_start と query_done を対象として、発行されたクエリを文字列として得ることができるので、以下のようなbpftraceのMap型を利用した面白機能を実装可能である。
# bpftrace -e 'usdt:/usr/pgsql-11.2/bin/postgres:postgresql:query__start {
@start = nsecs; } usdt:/usr/pgsql-11.2/bin/postgres:postgresql:query__done { @query[str(arg0)] = (nsecs - @start) /1000;} END { clear(@start); }' -p <pid>
例えば以下のような結果を得られるだろう。
... @query[UPDATE pgbench_tellers SET tbalance = tbalance + 4794 WHERE tid]: 101 @query[UPDATE pgbench_tellers SET tbalance = tbalance + 4729 WHERE tid]: 101 @query[UPDATE pgbench_tellers SET tbalance = tbalance + 443 WHERE tid ]: 102 @query[SELECT abalance FROM pgbench_accounts WHERE aid = 82619;]: 102 @query[UPDATE pgbench_tellers SET tbalance = tbalance + 3678 WHERE tid]: 102 @query[UPDATE pgbench_tellers SET tbalance = tbalance + -2676 WHERE ti]: 102 @query[UPDATE pgbench_tellers SET tbalance = tbalance + 2617 WHERE tid]: 102 @query[UPDATE pgbench_tellers SET tbalance = tbalance + -884 WHERE tid]: 102 @query[UPDATE pgbench_tellers SET tbalance = tbalance + -1229 WHERE ti]: 102 ...
pgbench で起動したクライアントに対応するバックエンドプロセスにアタッチしたものであるが、要するにどんなクエリが発行されたかとそれのdurationを query_start と query_done のタイムスタンプの差分として出力している。
USDTのargsから得られるクエリ文字列が切れてしまったりしているので、もしかしていまのUSDTの実装的に最大長があるのかもしれず、全然実践向きでないが。面白機能としては楽しめる。
ヒストグラム
最後に見た目的に面白い機能として、hist() について。
上記のdurationのワンライナーをすこしいじって、最後にヒストグラムが出力されるようにする。
bpftrace -e 'usdt:/usr/pgsql-11.2/bin/postgres:postgresql:query__start { @start = nsecs; } usdt:/usr/pgsql-11.2/bin/postgres:postgresql:query__done { @ret = hist((nsecs
- @start) /1000);} END { clear(@start); }' -p <pid>
例えば以下のような結果を得られるだろう。
@ret: [4, 8) 41 |@ | [8, 16) 589 |@@@@@@@@@@@@@@@@@@@@ | [16, 32) 71 |@@ | [32, 64) 540 |@@@@@@@@@@@@@@@@@@@ | [64, 128) 1474 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@| [128, 256) 452 |@@@@@@@@@@@@@@@ | [256, 512) 6 | | [512, 1K) 0 | | [1K, 2K) 0 | | [2K, 4K) 0 | | [4K, 8K) 0 | | [8K, 16K) 788 |@@@@@@@@@@@@@@@@@@@@@@@@@@@ | [16K, 32K) 201 |@@@@@@@ | [32K, 64K) 281 |@@@@@@@@@ | [64K, 128K) 280 |@@@@@@@@@ | [128K, 256K) 180 |@@@@@@ | [256K, 512K) 32 |@ | [512K, 1M) 3 | | [1M, 2M) 0 | | [2M, 4M) 0 | | [4M, 8M) 0 | | [8M, 16M) 0 | | [16M, 32M) 0 | | [32M, 64M) 0 | | [64M, 128M) 0 | | [128M, 256M) 0 | | [256M, 512M) 0 | | [512M, 1G) 0 | | [1G, 2G) 0 | | [2G, 4G) 1 | |
このままの実装だとクエリの内容は度外視であるが、アタッチしたプロセスが発行したクエリのdurationの分布を確認できている。
もうすこし凝ったことをしてクエリの内容と関連付けられれば何かが捗るかもしれない。そこまでやるにはbpftraceというよりもBCCスクリプトを自分で書いたほうがよりベターだとは思う。
まとめ
bpftraceのワンライナーでいろいろできることを確かめた。
bpftrace自体は、可観測性ツールという分野以外にも、なにやらTetrisを実装したりキータイピングのkprobeにフックしてオーディオ処理をしたり、楽しいハックがたくさんあるっぽい。